
A Markov Decision Process (MDP) is a powerful way to allow AI to make decisions in uncertain environments. In this project, I used the algorithm to provide the optimal strategy for Blackjack. I then compared the strategy to a widely available “Blackjack Cheat Sheet”, and found the strategy provided by MDP and the cheat sheet to have comparable performances of expecting to lose only 5¢ on a $10 bet, which is around the “house advantage” of 0.5% to the casino, indicating that it is indeed an optimal policy.
MDPs and Blackjack Rules
Traditional MDPs are most applicable to situations where the decision space is finite and discrete, the outcomes are uncertain, and the terminal state and its rewards are well defined. Furthermore, the situation must be made to abide by the Markov assumption, that the next state is a stochastic function of only the current state and the action applied.
Blackjack is played against a dealer, where the player is dealt two cards and the dealer exposes one card. The player aims to get the total face value of his or her set of cards as close to 21 without going over. Using the knowledge of their own cards and the single exposed dealer card, they must choose to either Hit (where they are dealt an additional card), Stay (where they attempt to beat the dealer with the cards they currently have), Double Down (where they hit and double their current bet), or Split (where if they currently hold two cards that are a pair, they split the pair into two hands, add the same bet to the additional hand, and hit on both). If the player hits in any form and busts (by going over 21), they lose. Else, if they stay, the dealer exposes another card, and must hit as long as their total value is less than 17, and stay otherwise. If the dealer busts or stays with a value lower than the player’s, the dealer loses. Else if their value is the same, they push (no reward), and otherwise, the player loses. The last relevant rule is that if the player or dealer hold an A, the value held by the A is a ‘soft’ 11, meaning it holds a value of 11 so long as doing so doesn’t make the hand’s total value exceed 21. Otherwise, the A takes a value of 1.
Blackjack meets the characteristics for applying an MDP because the players state can be defined by the total value of the hand they hold, whether or not it is a pair, and whether or not the hand is ‘soft’ (with an A acting as an 11). The dealer’s state is defined entirely by the value of the single card displayed, and thus the entire game’s finite state space is defined by the player’s state and the dealer’s state. Furthermore, the next state of the game is stochastically defined completely by the current state and the player’s action (Hit (H), Stay (S), Double Down (DS), or Split (SP)).
Solving an MDP gives us an optimal (reward maximizing) action (H, S, DD, SP) for a every possible state. For an MDP that has 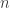
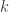

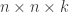




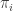

Framing Blackjack as an MDP
Thus in order to get the optimal strategy for Blackjack, we must first enumerate and encode the possible states of the game, and then compute
- Infinite decks: if we assume that cards are being drawn from an infinite set of decks (typically at least four), then no advantage is gained from keeping track of the specific cards open, but mostly just their face value, dramatically reducing the number of required states.
- Constant Marginal Utility of Money: If we assume that the player is indifferent between doubling from $10 to $20 and doubling from $20 to $40, then we only need to keep track of whether the player has ever doubled down, and not the number of times they did. The reason for this is that with the assumption, we only care about whether we should double down from a game state that we haven’t doubled down yet. If we want to know whether we should do so from the new state, we can use the decision policy of the equivalent state assuming we hadn’t doubled down yet. Thus we can use a simplifying rule that is a player can only double down one time.
- Using the first two assumptions, we can also see that if we split, the strategy used given either hand is not affected by the state of the other, and so we only need to keep track of one of the hands in our state.
Using these assumptions, we observe that the available states for the players hand are a Hard (no A acting as an 11) 5-21, Soft 13-20 (21 ignored because we know the strategy will be the same as if it were hard), Pair of 2-10 and A, giving us 35 possibilities. Note that all face cards are assumed to be 10. Additionally, the dealer’s hand could have an exposed 2-10 or an A, a total of 10 possibilities. Additionally, we keep track of whether or not we have doubled down as a binary state. The total number of combined states is 35*10*2 or 700 unique states. Lastly, we append on four terminal states (Bust, Lose, Push, or Win), giving us a total of 704 states.
With the states enumerated, the next step is to compute the transition probabilities from one state to the others given an action. Let us examine the Hit action for a Hard 5. This state can transition to a Hard 7-14 if any of the cards 2-9 are dealt, and thus transitions to these with a 1/13 probability. It can additionally transition to a Hard 15 with any of 10-K, so has a 4/13 probability. Finally, if an A is dealt with a 1/13 probability, it will transition to a Soft 16. If the action were a double down, the transition probabilities would be the same, but the transitions would be to the set of states assigned for having doubled down. As another example, if we hit on a pair of A’s, and a 7 is dealt with 1/13 probability, we transition to a Soft 18.
Carefully considering all possibilities, we can fill out the transition probabilities for the Hit, Double Down and Split actions. A quick bug-check is to ensure that the rows of
Lastly, we must fill out
The next step is to fill out the reward matrix
- If we bust by hitting from any normal state, we lose a nominal amount like $10.
- If we bust by hitting having previously doubled down, or doubling down, we lose double the nominal, so $20.
- If we lose by staying on a normal or doubled down state, we lose $10 or $20 respectively.
- If we win by staying on a normal or doubled down state, we win $10 or $20 respectively.
- If we make any other legal move, we get no explicit reward.
Having specified mdp_LP function asks for
Evaluating the Policy
The optimal policy returned by using an MDP is shown below, and compared to a “Blackjack Cheat Sheet”.

We can see a surprising amount of similarity for the Hard player hands, but some discrepancy for the Pairs and Soft hands. Though this discrepancy exists, the results still seem to line up reasonably with intuition. In fact, the cheat sheet seems to have some inconsistencies between Pair and Hard hand strategies – it recommends hitting regardless of the dealer on a Pair 6, but recommends staying for moderate dealer hands on a Hard 12, which is an identical hand under a Hit. These inconsistencies don’t seem as frequent in the MDP output.
To test the performance of these decision policies more rigorously, I performed a Monte Carlo simulation of 1,000,000 games for each policy, using this Blackjack simulator on MATLAB. The policies were also compared to a very naive policy of Staying no matter what your state. Using a $10 nominal bet per game, it was found that the MDP policy and the cheat sheet have expected losses of 6¢ and 4¢ respectively, but with standard deviations in these estimates (of expected loss) of 1.2¢. Using MATLAB’s ttest2 (two-tailed t-test) to test for a statistically significant difference in performance, we can assert that the cheat sheet is better with about 90% confidence.
On the other hand, the naive strategy has an expected loss of a much larger $1.6, with a standard deviation of 1¢ on that estimate. Using ttest2, we can assert that the MDP strategy is better with near perfect confidence.
While the difference between the MDP performance and that of the cheat sheet is very marginal, the likeliest for why is performs worse is that I made a small error in painstakingly filling out the almost two million state transitions probabilities in
Conclusion
The purpose of this project was to get familiar with using Markov Decision Processes to provide optimal strategies in discrete, finite state stochastic environments. Blackjack seemed to be a perfect candidate to try the algorithm on. To formulate the game in a manner acceptable to an MDP solver, I first specified the probabilities for transitioning from each gamestate to every other under all actions using either explicit analysis or Monte Carlo simulation. I then specified the rewards for transitioning from game states to terminal states under the different actions. With these matrices specified, I used the MDP solver to provide the optimal strategy. I compared this strategy to a widely available “Blackjack Cheat Sheet”, which claims to be the optimal blackjack strategy. Repeatedly simulating the strategies in the game of Blackjack, I found that both the MDP’s strategy and that of the cheat sheet lose only about 5¢ per $10 bet on average, while a more naive strategy loses $1.6 on the same bet. According to wizardofodds.com, the “house advantage” for a game of Blackjack with the assumed rules is around 0.5%. The house advantage indicates the expected value of the dealer assuming the player is playing optimally, and thus provides evidence that the strategy given by the MDP is indeed close to optimal.
I did this project with the help of Dilip Ravindran, a close friend and graduate student at Columbia Economics.
